
Learn
Best Video Streaming CDN in 2026? 7 Providers
Best CDN for Video Streaming in 2026: 7 Providers Compared A single rebuffer event at the two-second mark costs you 8% ...

A 100‑millisecond delay in page load time can drop conversion rates by up to 7% according to Akamai’s State of Online Retail Performance report — and that was before modern users got even less patient and more mobile-first.
When every millisecond can mean lost revenue, traditional cache-and-fetch CDNs are no longer enough. The new competitive edge is exactly that: the edge itself, now programmable through edge functions and serverless at the edge. Instead of just caching static files, your CDN can run logic closer to users than your origin ever could.
This shift is quietly rewriting how high-traffic platforms stream video, secure APIs, personalize content, and ship new features — often without touching their core backend at all. In this article, we’ll unpack how edge functions in CDNs work, where they shine, and how enterprises can use them to cut costs while delivering faster, smarter experiences worldwide.
Before we can appreciate edge functions, it’s worth remembering what CDNs used to be — and why that model is now under pressure.
CDNs originally solved a single problem: distance. By caching static assets (images, JS, CSS, videos) closer to users, they reduced round trips to centralized data centers. For years, that was enough. Web apps were simpler, pages more static, and user expectations lower.
Then mobile traffic exploded, single‑page apps took over, and experiences became highly personalized: pricing tailored to region, recommendations tuned to behavior, UIs adapted to device and network conditions. The bottleneck shifted from serving bytes to executing logic.
Yet that logic still lived in a handful of origin regions. Even with a CDN in front, every personalized decision — authentication, A/B test, geo‑routing, localization, paywall checks — often meant another trip back to the origin. The result: rising latency, higher origin load, and ballooning infrastructure bills.
Cloud providers and CDNs responded in two waves:
This second wave is where edge functions live: tiny, event‑driven pieces of code running in the CDN path — so close to the user that network distance almost disappears.
As you think about your own stack: how many of your current origin responsibilities are really just lightweight decisions that would be far better off executed at the edge?
This section gives you a precise mental model of edge functions so that design and cost discussions stop being vague.
At their core, edge functions are short‑lived, event‑driven programs that run inside a CDN’s infrastructure, typically triggered by HTTP requests and responses. You can think of them as programmable hooks in the delivery pipeline.
Common characteristics across major providers include:
In practice, edge functions in CDNs enable logic such as:
Unlike traditional origin‑bound serverless, edge functions execute in many locations worldwide, often just a few network hops from the user. That proximity is what makes them transformative for content delivery.
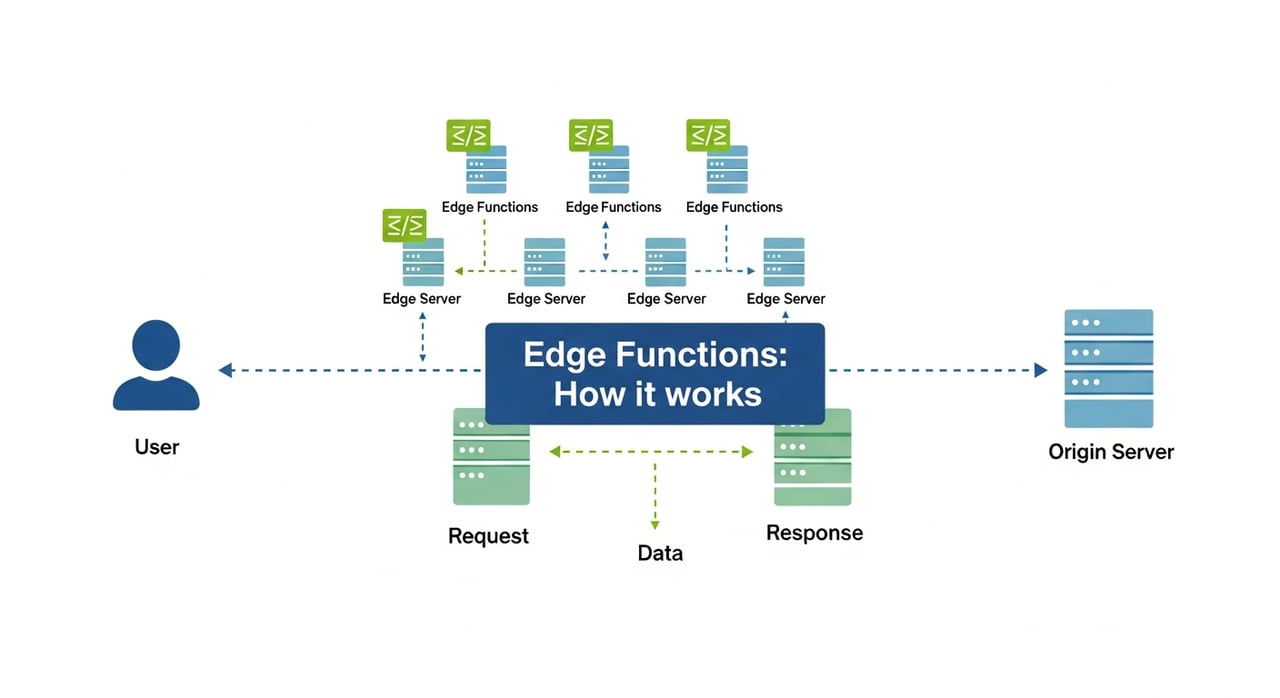
If you mapped your current request flow end‑to‑end, how many network hops and middleware layers stand between your users and the logic deciding what they see?
Here we connect edge functions to business outcomes: latency, reliability, and new capabilities that simply weren’t practical from centralized data centers.
Latency has a compounding effect. You feel it not just in initial HTML delivery but in APIs, client‑side hydration, and even analytics beacons. According to Akamai, just a 100 ms delay in load time can reduce conversion rates by 7% in e‑commerce. Google’s Milliseconds Make Millions study found that mobile sites loading one second faster could improve conversion rates significantly for several verticals.
Edge functions attack latency from multiple angles:
The net effect is faster Time to First Byte (TTFB) and more predictable performance, especially for globally distributed audiences hitting dynamic or semi‑dynamic endpoints.
Where are you still doing micro-decisions such as geo redirects, AB test splits, or minor auth checks on the origin that could be turned into near‑instant edge decisions?
As traffic grows, origin architectures typically evolve into sprawling clusters: application servers, API gateways, rate limiters, edge routers, and multiple layers of caching. Many of these components exist only because they must be as close as possible to users — but close used to mean in our main region.
With serverless at the edge, a meaningful slice of that logic can live directly in the CDN path:
This offload brings three concrete benefits:
Imagine your next capacity‑planning meeting: which services are you over‑provisioning today just to handle peak but trivial traffic that could be answered entirely at the CDN edge?
One of the classic tensions in web architecture is between performance and personalization. The more tailored an experience is, the harder it is to cache. Traditionally, that led to expensive and slow origin‑driven pages.
Edge functions enable a hybrid model:
For example, major streaming platforms use edge logic to enforce region‑based licensing, select nearby media servers, and choose appropriate bitrate ladders before the first chunk of video is streamed. Global e‑commerce companies localize currency and content, or gate promotions by market, directly in edge code, while still serving the bulk of HTML and assets from cache.
The result is personalization at CDN speed — a middle ground where you keep the benefits of caching while responding intelligently to who the user is and where they are.
If you could personalize three aspects of your experience without slowing pages down, which changes would bring the most revenue or engagement?
While full security stacks involve many layers, edge functions allow teams to implement custom security logic right where requests enter the system:
Because this logic runs extremely close to end users, bad traffic can be shaped or rejected early, saving origin resources for legitimate usage.
What security or compliance checks in your stack are effectively boilerplate, repeated across services, and would be cleaner as reusable edge logic instead?
This section gives you a side‑by‑side comparison so stakeholders can visualize trade‑offs when deciding how far to push logic to the edge.
| Architecture | Where Logic Runs | Latency | Operational Complexity | Typical Use Cases |
|---|---|---|---|---|
| Origin‑centric (no CDN) | Central data centers / cloud regions | Highest, especially for global users | High (you manage everything) | Internal apps, low‑traffic sites, legacy systems |
| Traditional CDN (static caching) | Origins + CDN cache for static assets | Improved for static content; dynamic still origin‑bound | Moderate (cache rules, invalidations) | Media delivery, simple websites, asset offload |
| CDN with Edge Functions | Origins + programmable CDN edge | Lowest for both static and many dynamic decisions | Higher design complexity, lower infra overhead | Global apps, APIs, streaming, dynamic personalization |
Seen through this lens, edge functions are not a replacement for origins but a powerful layer that changes what your origins need to do. They become systems of record and heavy compute engines, while the CDN becomes a programmable delivery and decision fabric around them.
Looking at your roadmap, are you still treating your CDN as a dumb cache, or are you designing features with the assumption that the edge is a first‑class compute tier?
Now we move from theory to patterns you can adopt, many inspired by how large platforms use edge compute to keep experiences fast and resilient.
Modern CDNs use edge functions to decide, in microseconds, where each request should go:
Large SaaS and streaming platforms rely on this pattern to run continuous deployments and regional migrations with minimal user impact. Instead of baking routing logic into application servers or Kubernetes ingress layers, they move it into the edge so it’s consistent across all clients and channels.
If you could promote or roll back a new backend version just by flipping an edge routing rule, how much release risk and downtime could you remove from your deployment pipeline?
A/B tests often introduce subtle performance regressions: client‑side JavaScript waits for a decision, or servers call out to third‑party flag providers. Edge functions can perform experiment assignment and flag evaluation as part of the request lifecycle:
Major experimentation platforms increasingly expose edge SDKs for this reason: the decision belongs where it can be made fastest, not buried in a monolith or client bundle.
How many of your just one more experiment decisions currently add script weight or backend hops that could be removed with edge‑side flag evaluation?
As microservice architectures proliferate, frontends often need to call multiple APIs to assemble a single page or app view. Without care, this leads to chatty networks and cascading latency.
Edge functions can act as a lightweight API gateway:
This pattern keeps frontends simple and mobile clients lean, while centralizing cross‑cutting concerns in a place that is globally close to users.
What percentage of your frontend latency is actually due to multiple API calls that could be merged or cached through an edge aggregation layer?
SEO teams often need fine‑grained control over redirects, canonical URLs, and header strategies. Implementing these rules directly in application code leads to brittle deployments and complex release coordination.
With edge functions, teams can:
Because changes deploy instantly at the CDN layer, SEO and growth teams can iterate faster and respond to market changes without waiting for full backend releases.
How many redirect or URL mapping rules in your backlog could move out of application code and into a centrally managed edge ruleset?
Video platforms, live sports broadcasters, gaming companies, and real‑time collaboration tools care deeply about latency, jitter, and packet loss. Edge compute plays a growing role here as well:
Real‑time analytics and QoE (Quality of Experience) metrics can also be ingested at the edge, sampled, enriched, and forwarded in aggregated form to central systems, reducing bandwidth and processing costs.
If your next big event drew 10× normal traffic, would your current origin‑centric architecture survive, or would you rather have edge logic absorbing and shaping that surge first?
Edge compute has its own constraints. This section covers the patterns that let you benefit from the edge without re‑creating monoliths in a new place.
Edge environments favor small, focused units of logic. Resist the temptation to port entire services to the edge. Instead:
This improves reliability, makes rollbacks safer, and keeps costs predictable.
Because edge functions often run far from your primary databases, they work best with:
Many teams adopt a configuration at the edge, critical data at the origin split, where only hard personalization (for example, account balances) requires origin access, while soft personalization (for example, content variants) uses edge‑resident data.
Because edge logic is distributed and co‑located with your CDN, debugging production issues can be non‑obvious. Invest early in:
Treat edge observability as first‑class; without it, the benefits of distribution can quickly turn into confusion during incidents.
Just as with backend services, rollouts should be gradual:
Edge functions operate at incredible scale — a small bug can impact millions of requests per minute. Guardrails and progressive delivery are non‑negotiable.
Looking at these principles, which ones would require the biggest mindset shift for your current development and operations teams?
Here we align edge functions with finance and infrastructure strategy: why they can lower total cost of ownership while increasing resilience.
Enterprise leaders often ask a simple question: does moving logic to the edge make things more expensive or less? The honest answer is: it depends on how you design and what you measure — but when implemented thoughtfully, edge functions tend to reduce overall costs.
Every request served or shaped at the edge is one that your origin doesn’t have to handle in full. Typical savings come from:
For high‑traffic streaming, gaming, and SaaS platforms, even single‑digit percentage improvements in origin offload translate into significant savings on cloud bills.
Traditional architectures require origin capacity to handle peak plus margin — including flash sales, product launches, and major live events. This often means running expensive infrastructure underutilized for most of the year.
With serverless at the edge, much of the burst can be absorbed in a highly elastic layer designed precisely for spiky workloads. Because many edge platforms bill per request and compute unit, you pay directly in proportion to actual usage rather than for idle capacity.
Modern enterprises increasingly look for CDN partners that combine high performance with predictable, transparent pricing. BlazingCDN was built with exactly this in mind: a high‑throughput, fault‑tolerant delivery platform that offers stability and fault tolerance comparable to Amazon CloudFront, but with a dramatically more cost‑effective pricing model.
For organizations delivering large volumes of media, software, or API traffic, BlazingCDN’s starting cost of just $4 per TB ($0.004 per GB) can reduce delivery spend by tens or hundreds of thousands of dollars annually, without compromising on uptime — backed by a 100% uptime track record. This makes it especially attractive for enterprises and corporate clients that need both reliability and aggressive cost optimization.
Companies in sectors like video streaming, online gaming, software distribution, and SaaS can use BlazingCDN to scale quickly for global product launches or seasonal spikes while keeping infrastructure lean and configuration flexible. It’s already recognized as a forward‑thinking choice for organizations that refuse to trade performance for efficiency.
As you evaluate providers, it’s worth exploring how BlazingCDN’s powerful rules engine and flexible delivery options can underpin your own edge‑first roadmap via BlazingCDN's enterprise-ready CDN features.
If finance asked you tomorrow how you plan to cut delivery and origin costs next year, could you show a clear path that includes programmable edge offload as a major lever?
This section turns concepts into a practical rollout plan: where to start, how to limit risk, and how to demonstrate quick wins.
Start by mapping your typical user request from browser or device to response:
Mark every place where the origin is used primarily for lightweight logic rather than heavy business rules or data access. These are prime candidates for edge migration.
Common starter projects include:
These changes are easy to validate, often reversible with a single configuration switch, and can deliver visible performance or operational wins within days or weeks.
Before rolling out edge logic across all traffic:
This foundation turns edge functions from an experiment into a dependable part of your production architecture.
Edge logic should be treated like any other code:
The more your teams see edge functions as a first‑class environment rather than an ops‑only configuration layer, the more value you’ll extract.
Once simple patterns are validated, you can move on to higher‑value scenarios:
These deeper integrations are where organizations often see the biggest impact on both performance and cost.
If you picked one small edge function project to deliver in the next 30 days, which use case would both excite your team and convince leadership that edge compute deserves more investment?
We close by looking forward — and inviting you to take concrete next steps instead of treating edge functions as a future‑only topic.
Analysts like Gartner have forecast that by 2025, a majority of enterprise‑generated data will be created and processed outside traditional data centers or clouds. That shift isn’t just about IoT sensors or industrial systems; it’s about how every high‑traffic digital experience is architected. Edge‑native patterns — where CDNs, edge functions, and origins form a tightly integrated continuum — are rapidly becoming the default for companies that depend on digital performance as a core competitive advantage.
Whether you’re streaming content to millions, shipping frequent software updates to global users, or running a SaaS platform with strict SLAs, programmable edge capabilities are no longer a nice to have. They’re a way to reduce risk, shrink bills, and unlock features that were previously too slow or complex to ship.
The next move is yours. Map one key user journey, identify the slow or fragile parts, and ask: what if this decision happened at the edge instead? Then start small, ship an edge function that removes a real bottleneck, and measure the impact. Share those numbers with your team — and with leadership.
If you’d like to explore what an edge‑forward CDN strategy could look like for your organization, bring your toughest performance or scaling challenge and start a conversation with your infrastructure, product, and finance stakeholders. Then, compare how different providers address those needs — and how a modern, cost‑efficient platform like BlazingCDN can become the foundation for the next generation of your content delivery stack.
When you’re ready, share this article with your team, bookmark it for your next architecture review, and start drafting your first edge function use case — because the edge isn’t just where content is delivered anymore; it’s where your competitive advantage will increasingly be decided.
Learn
Best CDN for Video Streaming in 2026: 7 Providers Compared A single rebuffer event at the two-second mark costs you 8% ...

Learn
Video CDN Providers Compared: BlazingCDN vs Cloudflare vs Akamai for OTT If you are choosing a video CDN for an OTT ...

Learn
Video CDN Pricing Explained: How to Stop Overpaying for Streaming Bandwidth Video already accounts for 38% of total ...